Three terms cropped up repeatedly this year: knowledge graphs, metadata, and AI governance. This post is one of our occasional explainers, designed to save you a heap of further reading, and to help you understand why this next wave matters now, not later.
Some of us spend a disproportionate amount of our working lives at London Excel. It’s Docklands’ answer to the question, “Can you build a moderately accessible, vast yet entirely soulless event space? No, no… we won’t need decent Wi-Fi; the internet’s a fad.”
Excel events can blur into a generic round of exhibition stands and free pens. But the Gartner Data and Analytics Summit is an exception. It’s reassuringly expensive, and therefore light on tyre-kickers, snake oil salesmen, and tote bag collectors. Instead, it’s three solid days of expert speakers and evidence-informed sessions, all focused on making your organisation future-ready through the lens of data and analytics.
Unsurprisingly, generative AI dominated the 2025 agenda—for the third year in a row.
(Also: they laid on Wi-Fi so fast and stable you could livestream the sessions you couldn’t squeeze into while queuing for [pretty decent] coffee. Credit where it’s due.)
From pilots to platforms
At Gartner’s London 2025 summit, everyone was still talking about RAG and agents—but this year, the conversation moved forward. Not because those ideas are past their peak. Far from it. They’re still at the heart of what smart, practical AI implementation looks like. But Gartner’s job is to ask “what’s next?”—to help those already experimenting start thinking about scale, sustainability, and governance.
Most organisations have now dipped a toe in the water. We’ve seen what’s possible. Now we’re asking more structural questions:
• How do we make AI trustworthy and repeatable?
• What does good actually look like?
• And how do we make our knowledge work harder for us?
Three terms cropped up repeatedly this year: knowledge graphs, metadata, and AI governance. Not exactly clickbait—but bear with me. This post is one of our occasional explainers, designed to save you a heap of Googling and to help you understand why this next wave matters now, not later.
(Not very) old is gold: RAG still matters
Before we leap into the new, let’s be clear: RAG isn’t going anywhere. It’s still the foundation of most of the AI tools we build at Leading AI, and for good reason.
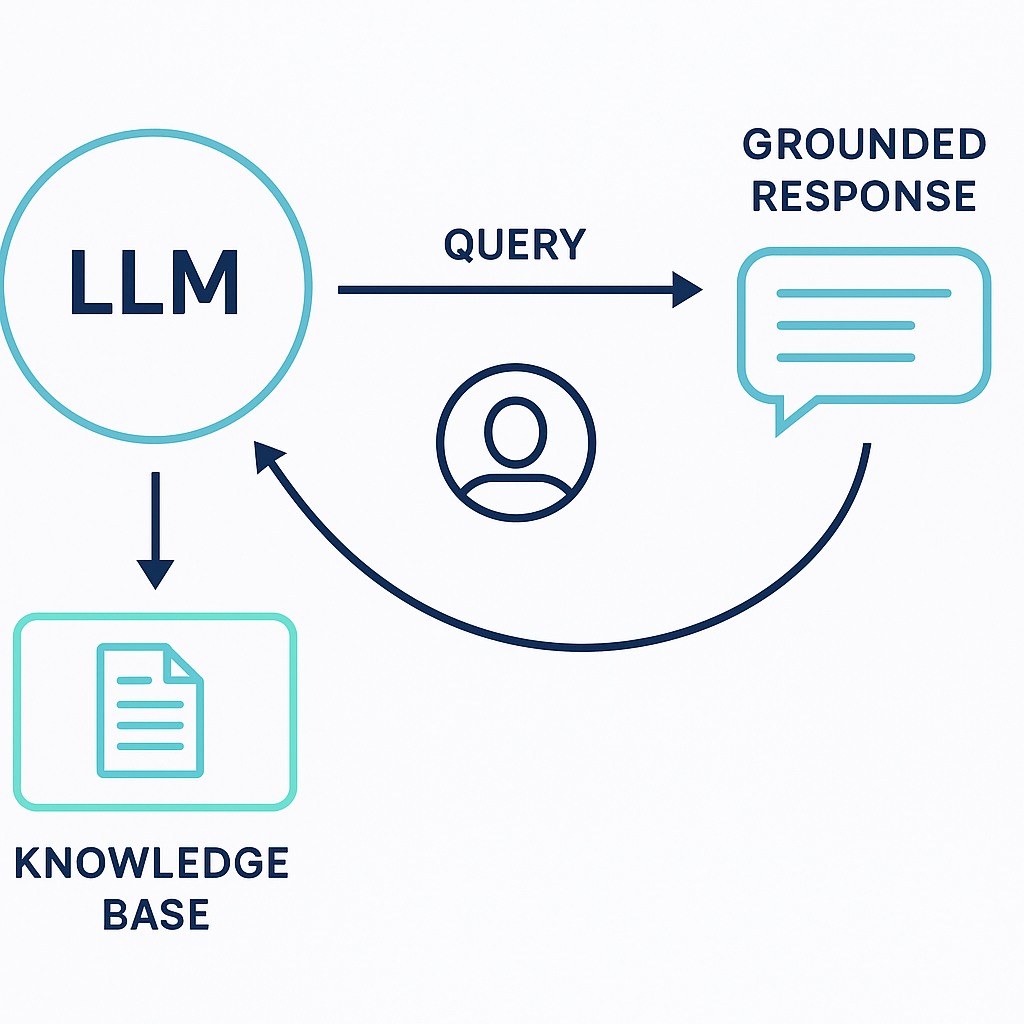
If you’ve used a private GPT trained on your own documents—like many of our customers have—you’ve used retrieval augmented generation (RAG). It’s what lets a large language model give answers based on your own data, rather than whatever it picked up on the open internet.
We wrote more about it here, but in short: RAG gives you answers that are accurate, auditable, and aligned with your organisation’s own policies. When hosted securely in your own systems, it also keeps your IP and data where it belongs—with you.
At Leading AI, we’ve used RAG to help local councils, colleges, companies and charities transform dense policy PDFs into something searchable, conversational, and genuinely helpful. These are tools for professionals who don’t want to scroll through 97 pages—but do want to make the right call.
That’s the difference between information being technically available and actually accessible.
Why the next wave matters
1. Learn about knowledge graphs
If RAG is about pulling the right information into your answers, knowledge graphs are about structuring that information in the first place.
Think of your organisation’s knowledge not as a filing cabinet of documents, but as a map of connected concepts—clearly labelled and linked. You can picture it like a tube map where each station is a topic, policy, or data point, and the lines are the relation-ships between them.
Say you’ve built a RAG-based HR assistant (and if you’re reading this, some of you know we’ve done just that). Staff can ask about entitlements or generate a training plan based on policy. Great. But what if that assistant could also consider related data: workforce trends, CPD records, sickness absence, EDI initiatives?
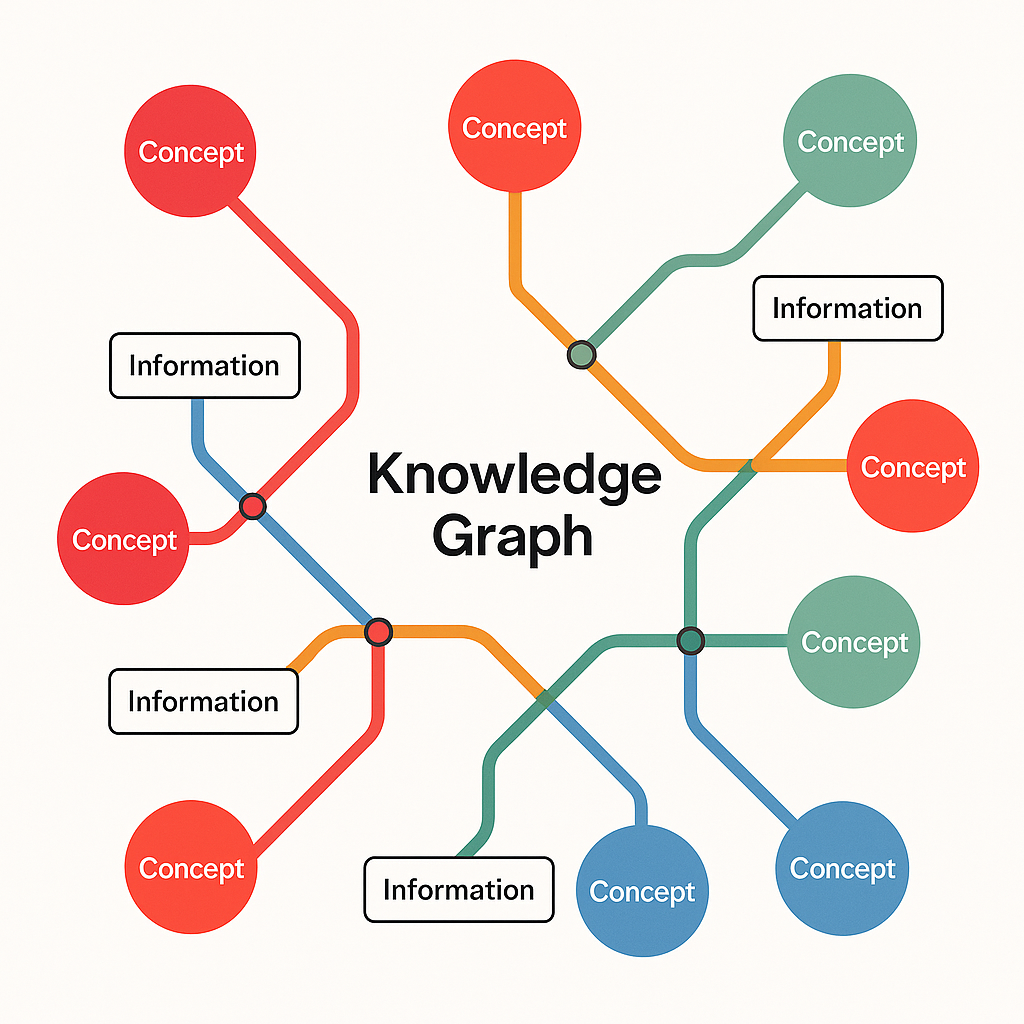
That’s where structured knowledge—enabled by knowledge graphs—comes in. It un-locks more sophisticated, cross-cutting insights. Suddenly, your AI isn’t just retrieving facts. It’s navigating context, spotting links, and helping you make better-informed decisions.
At the summit, this wasn’t pitched as a “next year” trend. It’s groundwork you can—and should—start now.
2. Actively manage your metadata
Metadata is often described as “data about data”. Here’s a better way to think about it: metadata is how your systems understand what a piece of information is, where it came from, and how it should be used, so it’s what makes data usable, explainable, and secure.
For example, a case record might include metadata about who created it, which system it came from, and whether it’s confidential. That same creator probably appears as an-other piece of metadata elsewhere. Maybe they approved a policy document in a data-base. Your organisation is storing an awful lot of metadata – are you using it generate insights?
Managing metadata isn’t glamorous, but it’s increasingly essential. Whether you’re pre-paring to use RAG or trying to get your data ready for something more advanced, start with an inventory. Then build a catalogue. Know what you’ve got and what state it’s in. Without that, you can’t deliver reliable AI—and you definitely can’t govern it.
3. Get serious about governance
Let’s be honest: governance doesn’t always spark joy. But at this year’s summit, it felt different. Less about abstract ethics, more about practical accountability.
We’re talking about version control, audit logs, permissions, oversight—the nuts and bolts that make AI trustworthy at scale. And not just in theory. Public services, healthcare, finance, education… every regulated industry now needs to be able to show its workings.
The questions have moved on from “should we use AI?” to:
• What happens when we do?
• Who’s accountable?
• How do we explain the results?
• Can we trace the decision trail?
Good governance is the framework that answers all of those.
The hype cycle meets the adoption curve
Gartner’s hype cycle is often misunderstood as a timeline. It’s not. It’s a way to map expectations. Some ideas hit the peak early—(remember blockchain for everything?)—then fall into what’s famously called the trough of disillusionment before slowly climbing toward practical usefulness. This is how the gen AI hype cycle looked by the end of 2024:
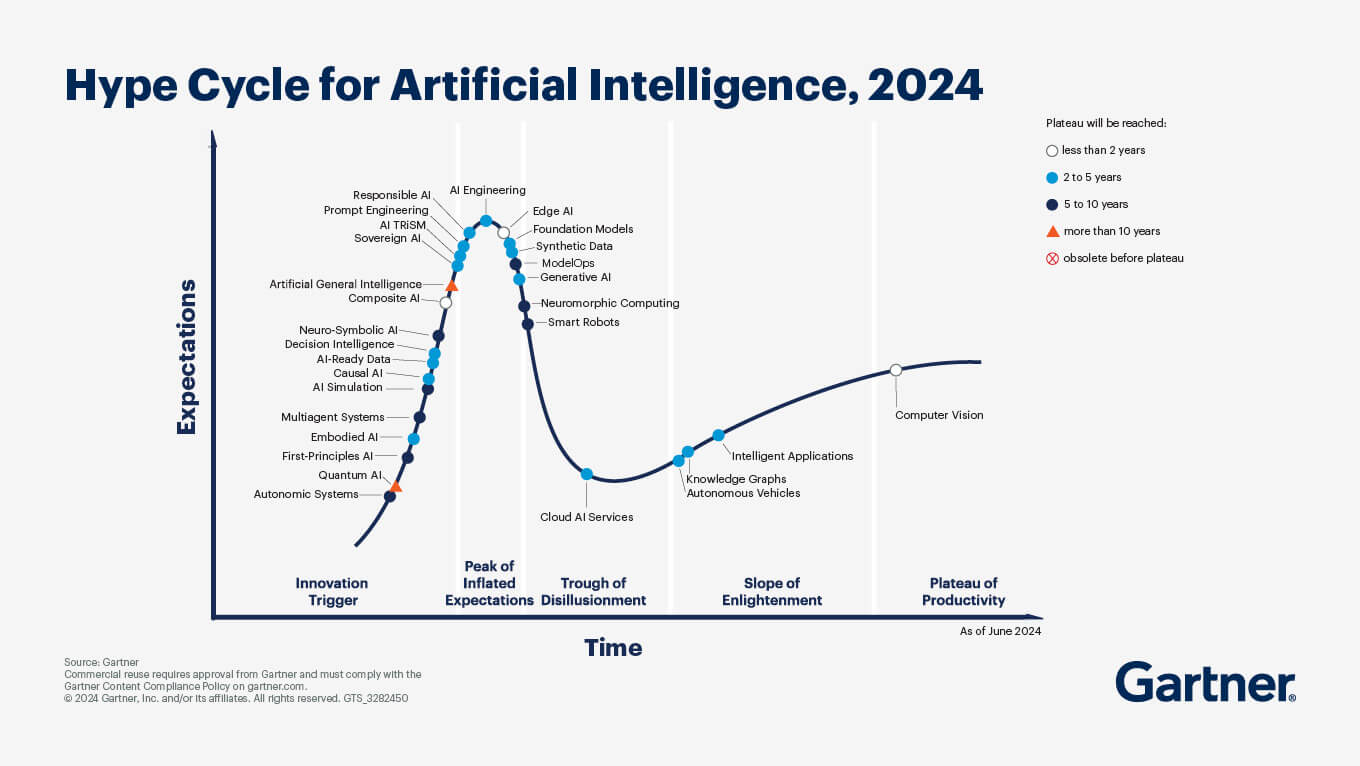
We’re seeing that pattern now with generative AI. It aligns closely with the innovation adoption curve—which we wrote about here.
The early excitement is giving way to serious delivery. Less talk of magic. More attention to models, meaning, and mechanics.
And that means tools like AI agents—which we covered here—aren’t being pushed aside. They’re just being embedded more carefully, with a growing awareness of when they should act, and when humans need to stay firmly in the loop.
So what should you do now?
First: don’t let this overwhelm you. If you’re reading about knowledge graphs and governance for the first time, that doesn’t mean you’re behind. It means you’re paying attention at the right moment.
If you’re just starting out, you don’t need to build a knowledge graph or launch a full governance framework tomorrow. Instead, start by asking:
• Do we know what data our AI tools are using—and how it’s described?
• Can we trace the path from prompt to answer?
• Are we confident we’ve structured our information in a way machines (and people) can understand?
And if you’re already using AI—especially tools based on RAG—you’re likely already laying the foundation for all of this. Every time you label a document, clean a dataset, or define what a “good” answer looks like, you’re building future-ready AI.
The future isn’t just about models. It’s about meaning. And the organisations that get that right—the ones who care as much about stewardship and structure as they do about speed—are the ones who will truly benefit.
________________________________________
* A very clever Gartner expert told me not to say metadata is “data about data.” He said the universe is a graph, and Earth is a subgraph, and that actually, everything is metadata. I think that was it. He was fascinating, and it was shortly after that I wished I’d brought our data analyst along to the session with me. It’s good to be reminded of your limits.